前言
在前端开发中,我们常常需要通过下载功能为用户提供文件。然而,这个看似简单的功能在实现过程中却可能遇到一些隐藏的性能问题。假设我们目前有一段代码,目的是给按钮注册一个点击事件,通过执行异步函数来下载文件:
async function () {
const response = await fetch('../xxx.pdf', {
headers: {
authorization: `Bearer token`
}
})
const blob = await response.blob()
const url = URL.createObjectURL(blob)
const a = document.createElement('a')
a.href = url
a.download = 'xxx.pdf'
a.click()
}这段代码看起来没有问题,而且下载功能也能正常运行。但是,如果你仔细思考一下,这种方式真的有效率吗?文件较大时是否会出现问题呢?
下载方式
在浏览器中触发下载通常有两种方式:客户端方式和服务端方式。
服务端下载方式
通过超链接来下载文件是最常见的方式。通常,链接指向文件的URL,例如:
<a href="....../xxx.pdf">Download</a>点击链接后,浏览器默认行为可能是打开 PDF 文件而不是直接下载。这时,我们需要服务端的配合,通过设置响应头来强制下载:
const app = express();
app.get("../xxx.pdf", (req, res) => {
res.setHeader("Content-Disposition", "attachment; filename=xxx.pdf");
res.sendFile(__dirname + "/xxx.pdf");
});在这个例子中,我们通过 Content-Disposition 响应头,将文件设置为附件格式,并指定文件名。当用户点击链接时,浏览器会自动开始下载,而不会在新窗口中打开文件。
客户端下载方式
<a href="xxx.pdf" download="xxx.pdf">Download</a>虽然这两种方法都可以触发下载,但如果需要对下载进行鉴权,就必须自定义点击事件。
深入分析
上面自定义点击事件代码的问题在于它对大文件的处理方式。假设你通过点击 HTML 超链接来下载一个文件,浏览器实际上是向服务器发起了请求,服务器将文件的数据一段一段地传输给浏览器。这种方式下,浏览器不会在本地保存数据,而是直接将数据流向用户选择的文件位置。
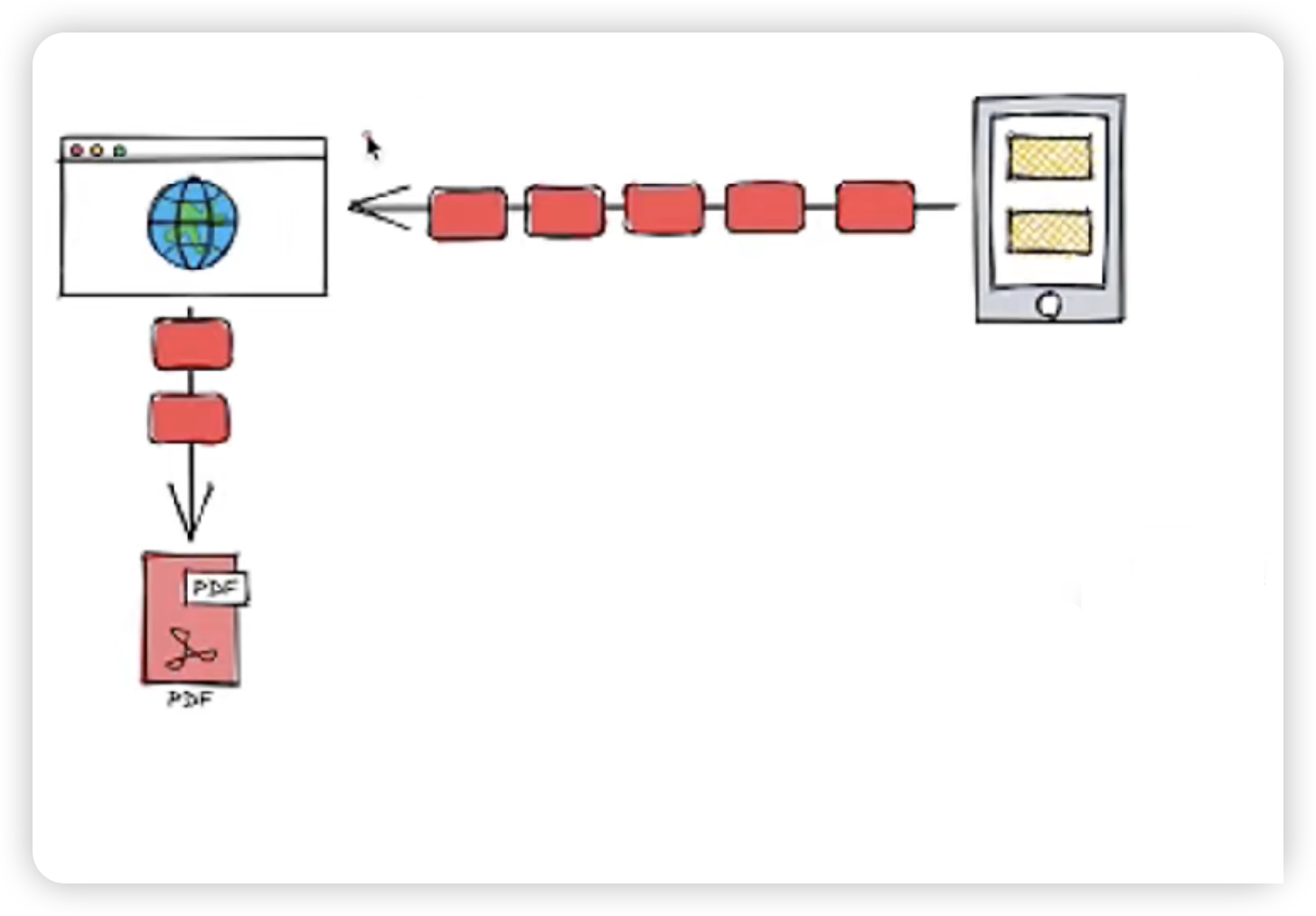
然而,如果使用自定义点击事件和 Ajax 方法来下载文件,就会出现问题:
const blob = await response.blob();这行代码会等到服务器把文件的所有数据都传输给浏览器并生成一个 blob 对象。在这种模式下,文件数据必须先全部传输到浏览器,才会生成 blob,然后再保存到本地文件。
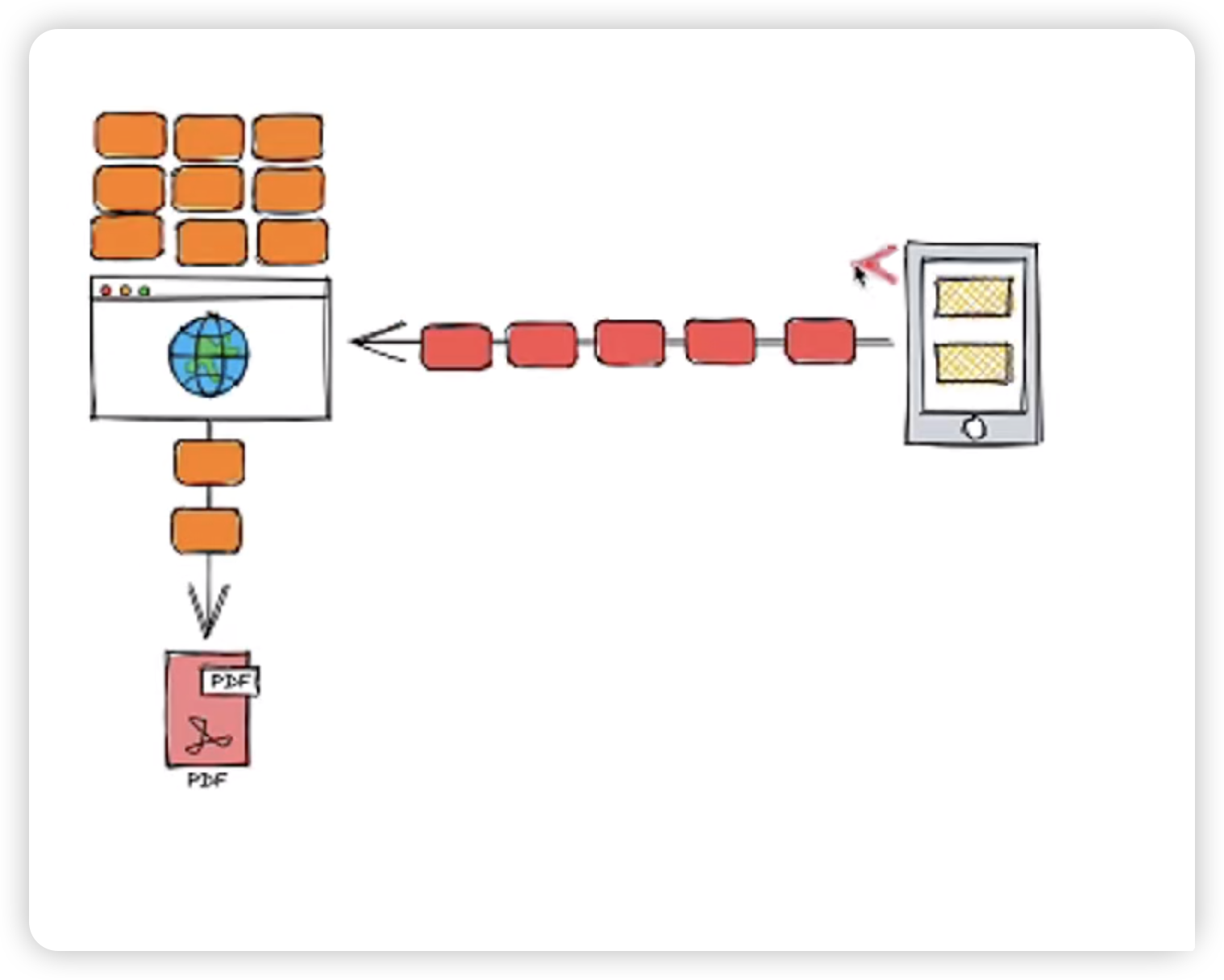
也就是说,如果文件有 100GB,浏览器就要先在内存中准备 100GB 的空间来存放这些数据。这可能会导致内存不足,从而影响浏览器和计算机的性能。
虽然现代浏览器会在数据过大时优化处理,比如使用临时文件或交换空间(SWAP),但这种方式依然不够高效。特别是在网络较慢的情况下,用户可能需要等待很长时间,直到所有数据传输完成后,下载才真正开始。
解决方案
流式下载的实现
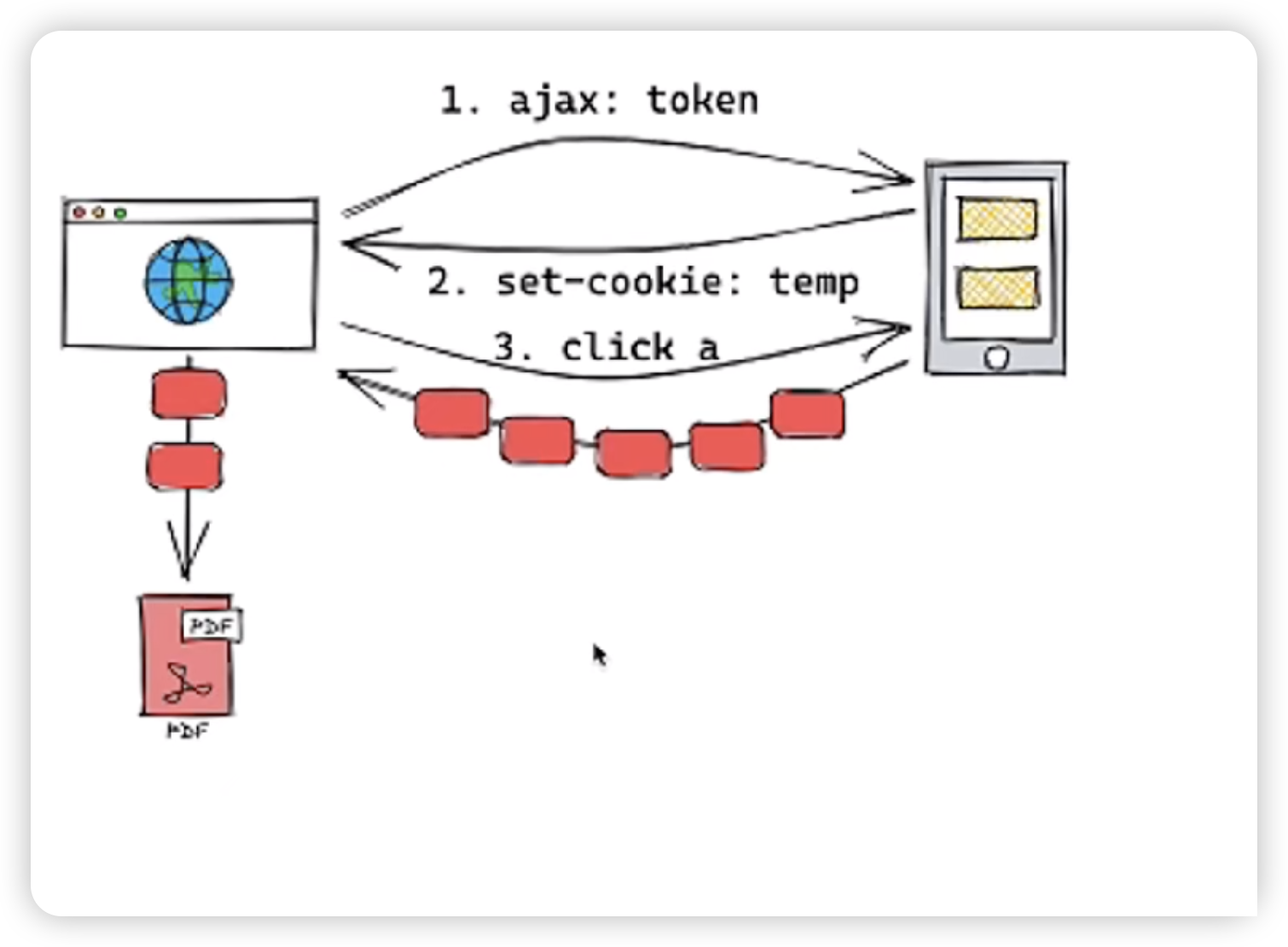
如果需要鉴权,我们可以在用户点击下载按钮时,先通过 AJAX 请求将 Token 发送给服务端进行验证。如果验证通过,服务端可以设置一个短期有效的临时 Cookie。然后,我们生成一个超链接指向文件的 URL,并自动点击该链接:
async function downloadWithAuth() {
// 验证 Token
const authResponse = await fetch("/auth", {
method: "POST",
headers: {
authorization: `Bearer token`,
},
});
if (authResponse.ok) {
// 设置了短期有效的 Cookie 后,生成超链接
const link = document.createElement("a");
link.href = "/download/xxx.pdf";
link.download = "xxx.pdf";
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
} else {
console.error("Authentication failed");
}
}在这个例子中,我们确保只有验证通过后才生成和点击超链接,这样浏览器的下载操作就可以直接与文件流式传输对接,而不必等待整个文件传输完成。文件数据会通过流式传输直接流向用户选择的保存位置,而不会占用大量内存。
服务端处理
const app = express();
app.get("/download/xxx.pdf", (req, res) => {
const isAuthenticated = validateCookie(req.cookies);
if (isAuthenticated) {
res.setHeader("Content-Disposition", "attachment; filename=xxx.pdf");
res.sendFile(__dirname + "/xxx.pdf");
} else {
res.status(403).send("Forbidden");
}
});在这种方案下,超链接指向实际文件的 URL,浏览器会处理流式传输,不会占用过多内存,确保用户有下载该文件的权限和流畅性。