前言
众所周知,DNS 是用来做域名解析的,当在网页 URL 中输入域名时,浏览器会通过 DNS 服务器解析得到一个 IP 地址,至于从DNS 转化到 IP 的过程比较复杂。这里不着重讨论。只需要知道:
- 从域名到 DNS 再到 IP,这一个转换的过程是耗时的,存在优化的空间。
- DNS 转化之后会做本地缓存。比方说你再次访问 Google 时,还是会解析,但这次是在本地缓存中解析到 IP 地址。
所以,我们优化的目标是针对用户第一次访问陷入长时间白屏的问题。
URL 到网页的过程
在我们优化之前,我们先看一张图,了解一下浏览器是如何加载一个网页的。
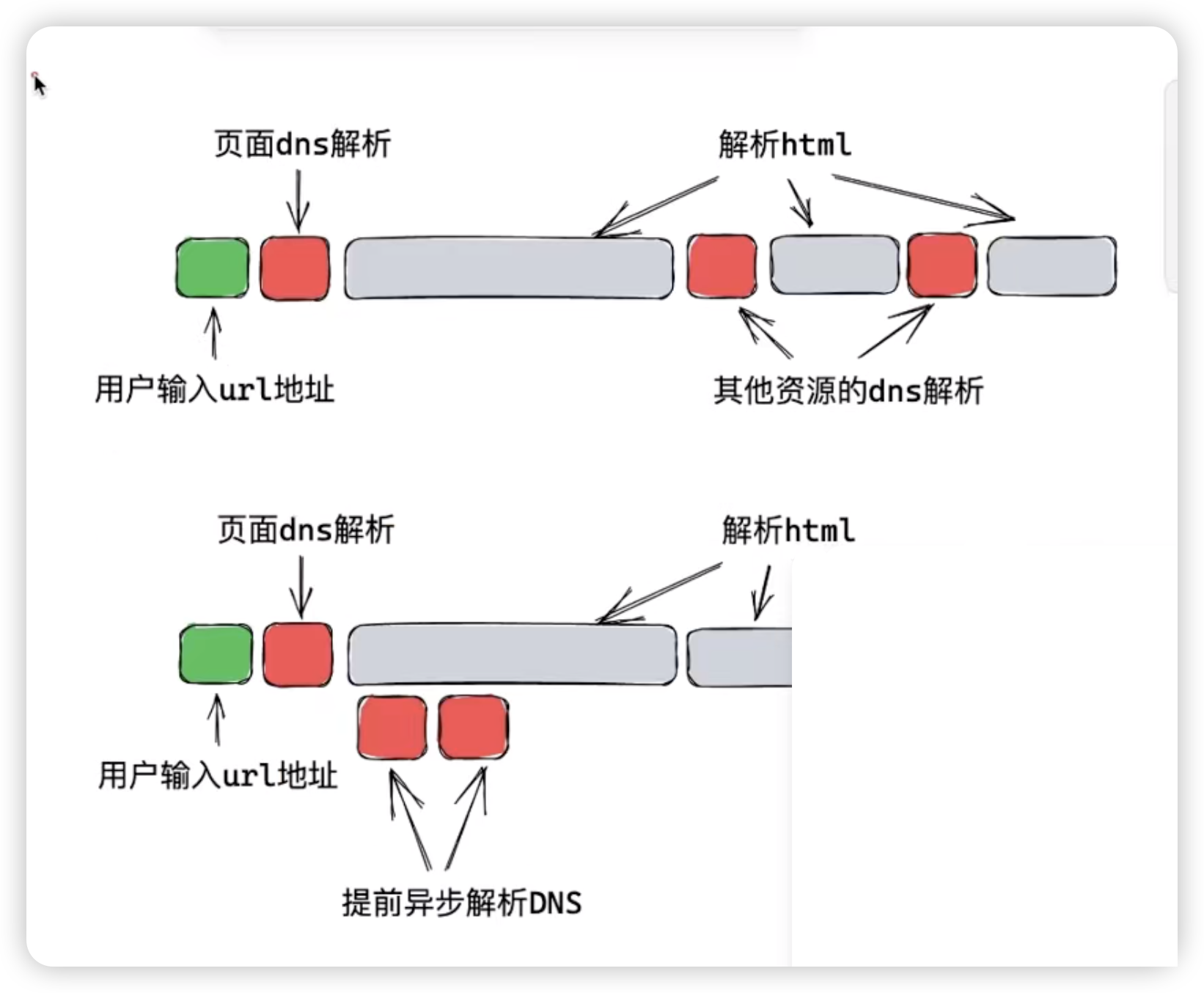
- 用户输入一个 URL 地址,浏览器首先要进行 DNS 解析,将域名转化为 IP 地址。这个过程是无法避免的,而且通常会花费一定时间。
- 浏览器接着向服务器发送请求,服务器返回 HTML 内容,浏览器开始解析这些内容并生成 DOM 树。
- 在解析过程中,浏览器会遇到一些
script、img或css这样的资源元素,这时它需要暂停解析并发起新的网络请求来获取这些资源,此时浏览器渲染主线程会被暂停,等资源元素加载完之后再继续渲染。 - 每次网络请求,如果是新域名,浏览器都需要再次进行 DNS 解析,这又会消耗时间。
- 最终,所有的资源加载完毕,页面才会完全呈现给用户。
如何优化
DNS 解析是不可避免的,但我们可以通过一些方法来减少它对页面加载速度的影响。我们的目标是让浏览器在正式解析 DOM 树之前,提前异步解析可能需要的 DNS。这样一来,当需要加载资源时,DNS 解析已经完成,可以直接加载资源,加快页面的加载速度。
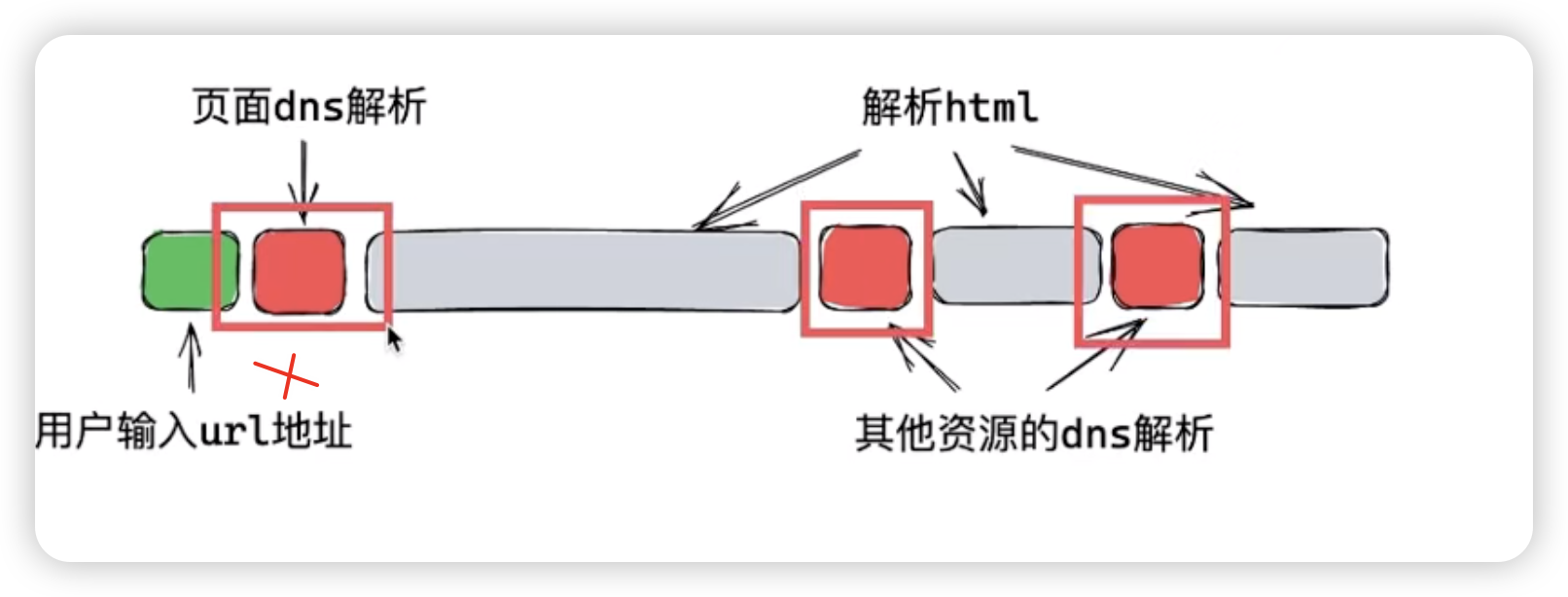
如上图所示,第一个位置是没有办法去优化的,那么我们从后两个步骤入手,让浏览器提前把 DNS 解析好,
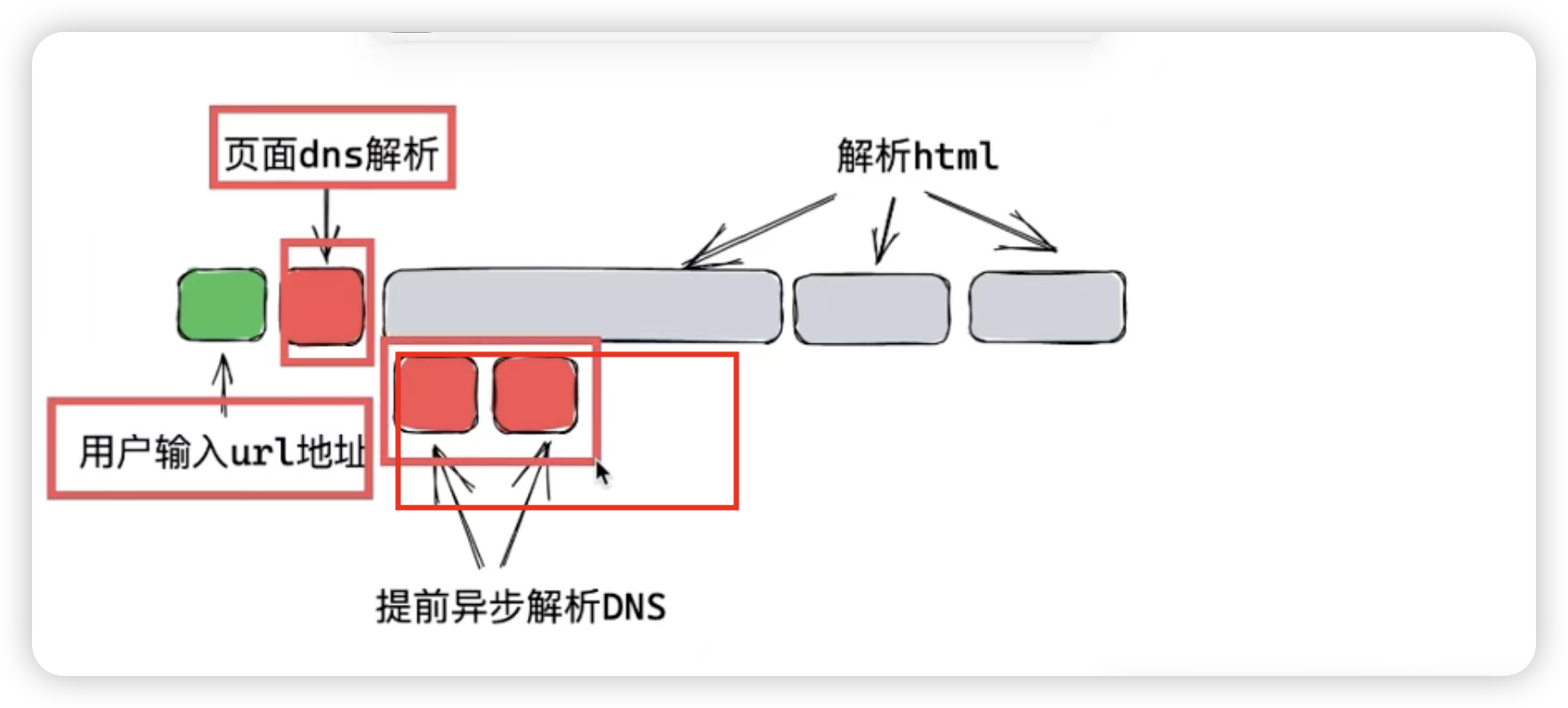
如上图所示,用户输入 URl 地址然后做页面级别的 DNS 解析,然后浏览器开始渲染页面,在解析 DOM 的时候,我们可以提前告诉浏览器,在提前异步解析DNS这里让浏览器把页面中后续要用到的一些域名,先进行提前 DNS 解析,那么后面需要请求其他资源的时候,就不用再进行DNS解析了,而且这种解析是异步的,它不影响浏览器解析我们的DOM树。那应该怎么做 ?
<html>
<link ref="dns-prefetch" href="cdn.resource.com" />
<link ref="dns-prefetch" href="cdn2.resource.com" />
</html>这种做法非常简单,但是在开发中,我们往往是通过框架来构建项目,很少直接写这样的 HTML 文件。因此,需要考虑在框架环境中如何实现这一优化。
比方说,这里有个 Vue 组件:
<template>
<div id="root">
<img src="//cdn.resource.com/xxx.jpg" />
<a href="//cdn2.resource.com" />
</div>
</template>
<style scoped>
body {
background: url("//cdn3.resource.com/xxx.jpg");
}
</style>其中 image,a 和 CSS Background 都使用了外链接,而且还不止一个,有多个文件使用到了外链接,你很难知道整个项目里边到底用了多少个外链接。
而且即使修改 Vite.js 提供的模板页面 index.html ,又该如何知道需要创建多少个 dns-prefetch link 标签呢?
工程化中的解决方案
在工程化环境下,我们可以通过编写插件来完成需求,但如果一个项目使用的 vue-cli 脚手架,就需要去编写 webpack 插件,而另一个项目使用 Vite.js 脚手架,那么需要编写 Rollup 插件。能不能有一个通用的解决方案?
我们可以编写一个 Node.js 脚本来自动完成这一任务。因为需要读取文件,所以运行环境是Node.js。
const { parse } = require("node-html-parse");
const { glob } = require("glob");
const fs = require("fs");
const path = require("path");
const urlRegex = require("url-regex");
// 获取外部链接的正则表达式
const urlPattern = /(https?:\/\/[^/]*)/i;
const urls = new Set();
// 遍历打包后的文件夹 dist 中所有的 HTML、JS、CSS 文件
/**
* @description 保存所有不重复的域名
*/
async function searchDomain() {
// 通过一个 glob 来匹配文件
const files = await glob("dist/**/*.{html,css,js}");
// 拿到文件后遍历
for (const file of files) {
const source = fs.readFileSync(file, "utf-8");
// 匹配每个文件里存在的链接
const matches = source.match(urlRegex({ strict: true }));
if (matches) {
// 匹配到域名之后添加到 Set 集合里,保证不重复
matches.forEach(url => {
const match = url.match(urlPattern);
if (match && match[i]) {
urls.add(match[1]);
}
});
}
}
}
// 将集合里所有的域名转为 link 标签
async function insertLinks() {
// 找到 html 文件
const files = await glob("dist/**/*.html");
// 用 map 将域名转为 link 标签
const links = [...urls]
.map(url => `<link rel="dns-prefetch" href="${url}" />`)
// 拼成字符串
.join("\n");
// 遍历所有的 HTML 文件(可能是多页应用)
for (const file of files) {
const html = fs.readFileSync(file, "utf-8");
// 读取每个 HTML 文件内容,转为 DOM 树
const root = parse(html);
const head = root.querySelector("head");
// 把所有 link 标签添加到 head 里
head.insertAdjacentHTML("after", links);
// 把变动的内容保存到每个 HTML 文件中
fs.writeFileSync(file, root.toString());
}
}
async function main() {
await searchDomain();
await insertLinks();
}
main();这个脚本的工作原理是:
- 搜索打包后的 HTML、CSS 和 JS 文件中的所有外部链接。
- 将找到的域名存储在一个集合中(保证不重复)。
- 将这些域名生成
dns-prefetch标签,并插入到所有 HTML 文件的<head>部分。
这样,每次打包之后运行这个脚本,便可以自动将 DNS 预解析的优化应用到项目中。通过这种方法,可以有效减少用户首次访问时的 DNS 解析时间,让网页更快呈现给用户。